

A complete technical SEO audit should check all the technical aspects of a site to make sure they are SEO-friendly. This means important technical aspects of your website that relate directly to ranking factors for search engines like Google.
Here are the key technical SEO elements we are going to touch up on to get a sense of the website’s technical backbone.
- Crawl Errors
- Canonicalization Issues
- Manual Actions Issues
- Indexing Issues
- Image Issues
- XML Sitemaps
- Site Architecture
- Mobile Optimization
- Page Load Speed
- Link Health
- Duplicate Content
- Schemas
- Site Security
- 404 Pages
Crawling
Crawling is the process where a search engine bot tries to visit each page of your website. A search engine bot finds a link to your website and starts to find all important pages from there. The bot crawls the pages and indexes all the contents for use in Google, main goal is to make sure the search engine bot can get to all important pages on the website.
Crawl errors occur when a website crawler tries to reach a page on your website but eventually fails at it.
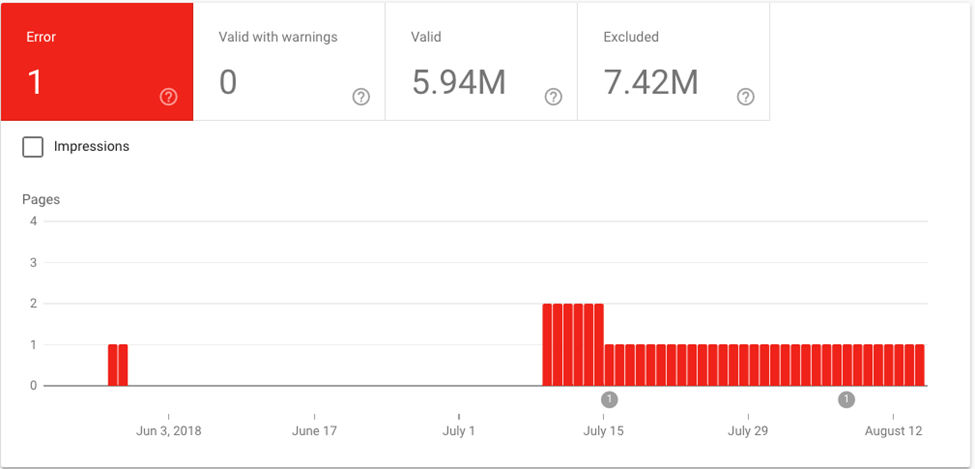
Recommendations:
· Remove the login from pages that you want Google to crawl, whether it’s an in-page or popup login prompt.
· Check your robots.
· Use the robots.
· Use a user-agent switcher plugin for your browser or the Fetch as Google tool to see how your site appears to Googlebot.
Canonicalization
A canonical tag is a way of telling search engines that the enclosed URL is the original, definitive version of the page. Canonical tag prevents problems caused by identical content is being found on multiple URLs.
Canonical issues commonly occur when there are two or more URLs with similar content on a website. While crawling pages search engines find it difficult to consider which page is the main page or the original page. That’s where canonical tags are used to instruct search engines which is the master version of the URL.
For example, a site might load its homepage for all of the following URLs:
- https://www.example.com
- https://example.com
- https://example.com/index.php
- https://example.com/index.php?r…
Recommendations:
- Double-check that your rel=canonical target exists (it’s not an error or “soft 404”).
- Ensure the rel=canonical target doesn’t contain a noindex meta tag.
- Include the rel=canonical link in either the <head> of the page or the HTTP header.
- Specify only one rel=canonical for a page. When more than one is specified, all rel=canonical links will be ignored.
Indexing
Indexing is the process of adding web pages into Google search after the crawling and rendering process. Depending upon which meta tag you used (index or NO-index), A index tag tells the search engine to show the page into a search engine. A no-index tag means that that page will not be added to the web search’s index.
To check the number of indexed pages of your website by Google, Simply type Site:xyz.com in the search bar as given below.
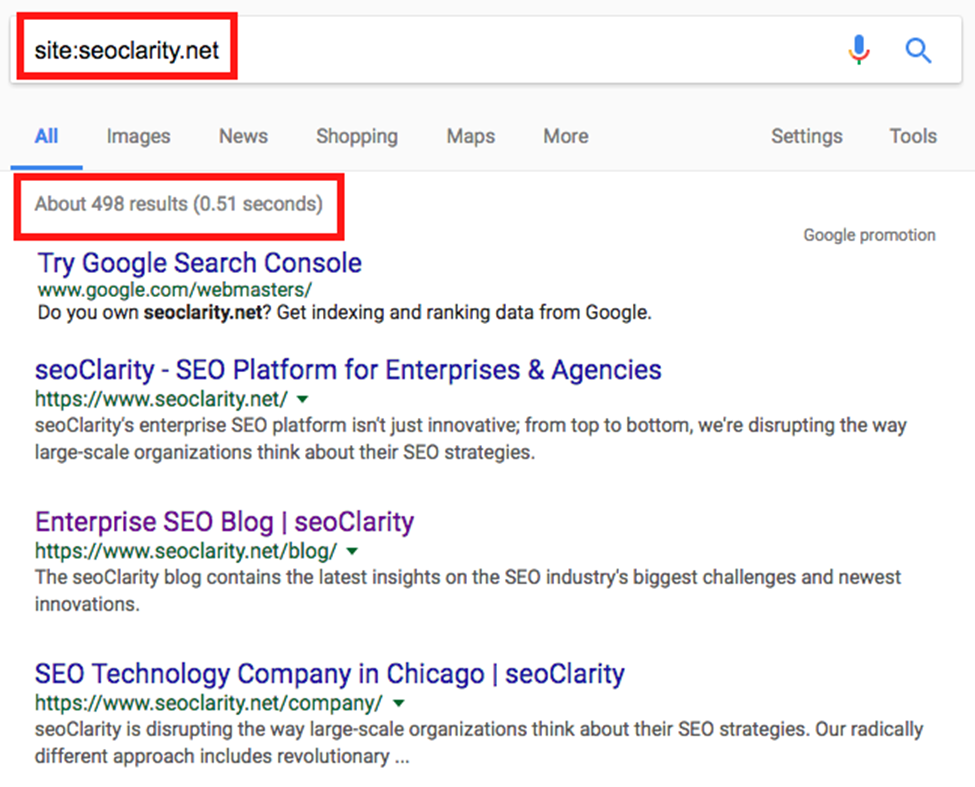
There are tags that are No index, no follow which prevents search engines from indexing certain pages on the website. Your website content is not properly optimized and does not also follow the keyword search intent. Your site suffers from internal or external duplicate pages.
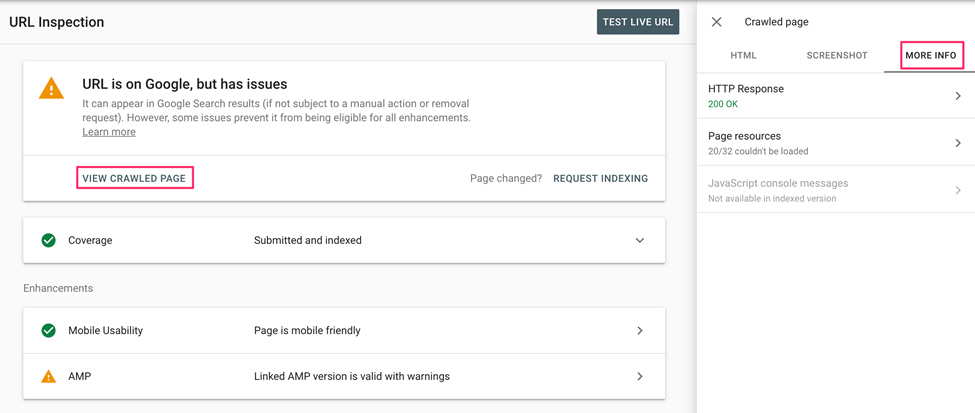
Recommendations:
- Remove the affected page URL from the sitemap and resubmit the sitemap in the Sitemaps report.
- Using the Sitemaps report, delete any sitemaps that contain the URL (and ensure that no sitemaps are listed in your robots.
Image Issue
Poorly optimized images are one of the main reasons for slow web pages, optimized images speed up page loading, which increases user engagement and search engine rankings.
Search engines crawl the text on your webpage as well as image file names. Therefore, optimizing file names is also crucial for image optimization for better website ranking.
Recommendation:
- Resize your images, pick the right file format, Choose the right compression rate and use the correct Image optimization tools.
- Optimize image file names, use alt tags, Optimize the image title, include captions, use unique images, ensure that your text complements the images, add image structured data and use image sitemap
XML Sitemaps
It is a type of file that contains all the important URLs of a website for crawling. It acts as a roadmap to tell search engines what content is available and how to reach it.
Some of the most common errors associated with sitemaps are:
- Submitted URL Not Found (404)
- Submitted URL Seems to Be a Soft 404
- Submitted URL Returns Unauthorized Request (401)
- Invalid Date
- Submitted Page Blocked by Robots.txt File
- Submitted URL Marked ‘no index’
- Too Many URLs in Sitemap
- Submitted URL Not Selected as Canonical
Robots.txt
A robots.txt is a text file that instructs crawling bots (typically search engine robots) how a web page needs to be crawled. Some of the following important things should look at while uploading the robots.txt file in the root directory of the site.
- Use of incorrect syntax
Robots.txt is a simple text file that always consists of two parts first part contains the user agent to which the instruction should apply (e.g., Googlebot), and the second part specifies commands, such as “Disallow”
Instructions for the correct syntax should be used as shown below.

In the above example, Google’s crawler is restricted from crawling the /example_directory/. If you want this to apply to all crawlers, you should use the following code in your robots.txt file:
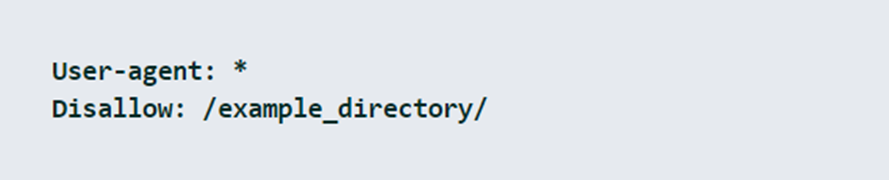
The Asterix (*) acts as a variable for all user agents like Googlebot and Bing Bot. Similarly, you can use a slash (/) to prevent the entire web page from being crawled.

- Blocking path components instead of a directory (forgetting “/”)
You should always add the slash at the end of the directory’s name to exclude a directory from crawling. If you want to exclude numerous pages from the indexing, you should add each directory in a different row.
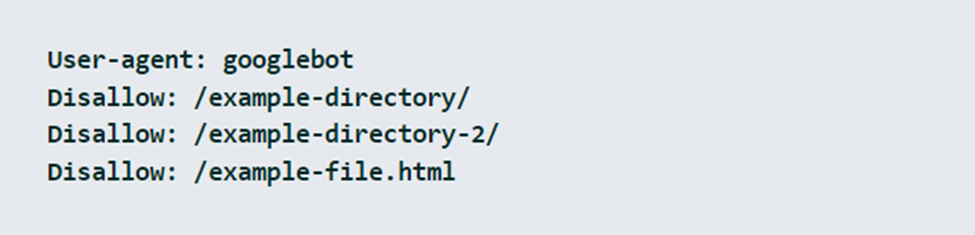
- Unintentionally blocking directories
Always make sure to check if the syntax is correct before the robots.txt file is uploaded to the root directory of the website.
Even the minor error could result in the crawler ignoring the instructions in the file and leading to the crawling of pages that should not be indexed. Always ensure that directories that should not be indexed, are listed after the Disallow: command.
- Not saving the robots.txt file in the root directory
The most common error is failing to save the file in the root directory of the website. The correct URL for a website’s robots.txt file should be:

- Disallow pages with a redirect: It is recommended not to let crawl pages with redirects through disallow directive to save crawl budget.
Mobile SEO
Mobile SEO is the process of optimizing your site for visitors on different screen sizes smartphones and tablets. Implementing mobile SEO for a site, you’ll provide a great site experience for visitors who access your site from mobile and tablet devices
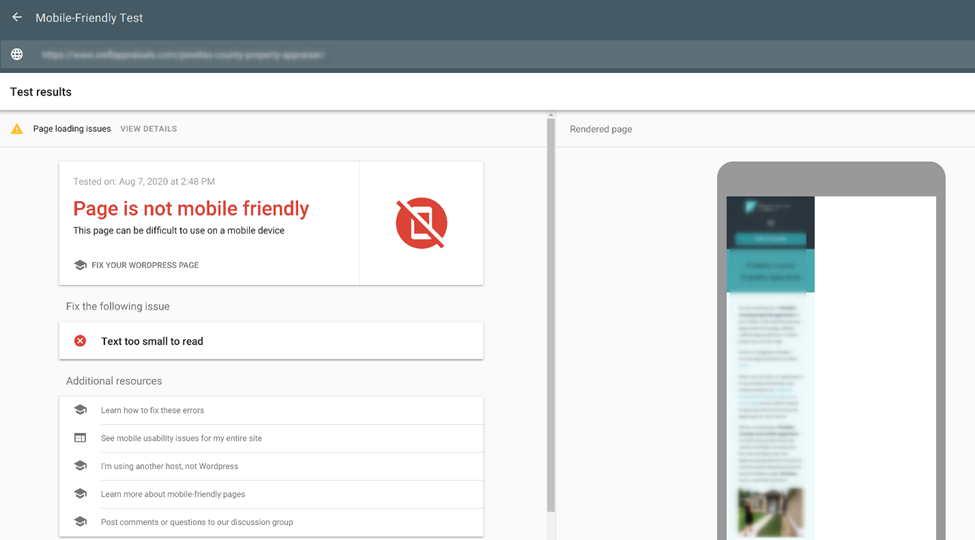
Recommendation:
- Don’t block JavaScript, CSS, and image files as it is against Google’s guidelines.
- Build a responsive website for a better user experience.
- Ensure any redirects to separate URLs are functioning properly according to each mobile device and no pages are hiding from Google due to robots.txt.
Fix faulty redirects and cross-links
Manual Actions
Manual Actions against a website or webpage mean that a human reviewer at Google has determined it is not compliant with Google’s Webmaster Quality Guidelines and has penalized your site.
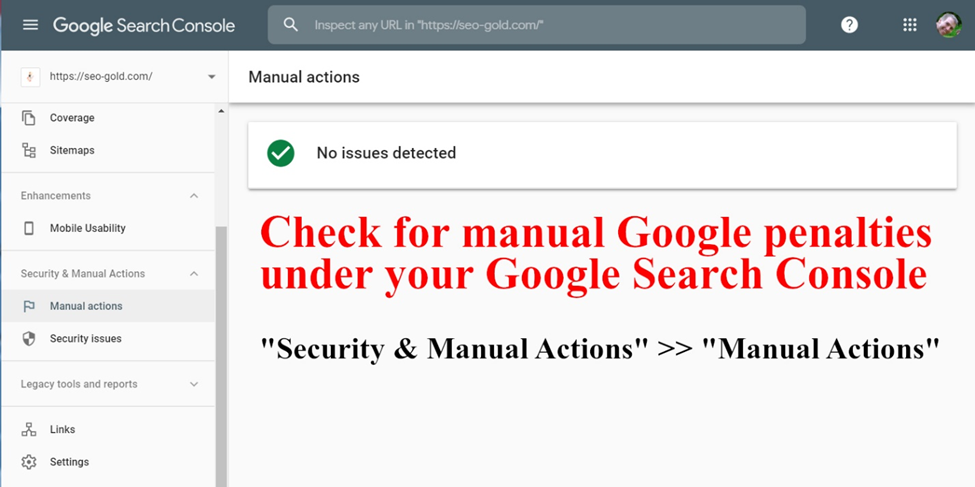
Manual Actions occur very rarely but are serious issues and could lead to a page demotion or removal from Google’s index. See if your site has any manual actions issued against it it’s possible your site can underperform due to it.
Website Architecture
Website architecture refers to a balanced website structure for better usability and crawlability. A website with good structure helps bots to crawl each on the website more efficiently.
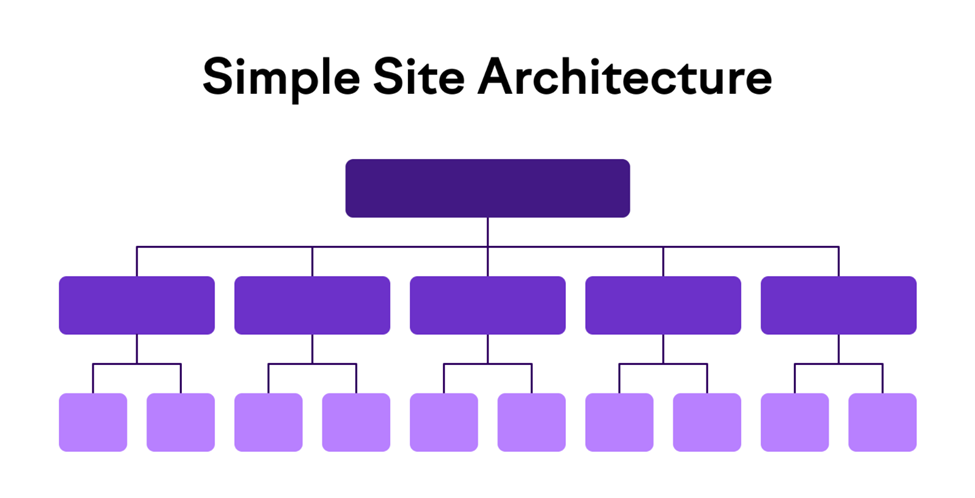
Here is the website with a bad structure which makes it hard for the crawl to reach to end pages of the site due to an insufficient crawl budget and bad internal linking.
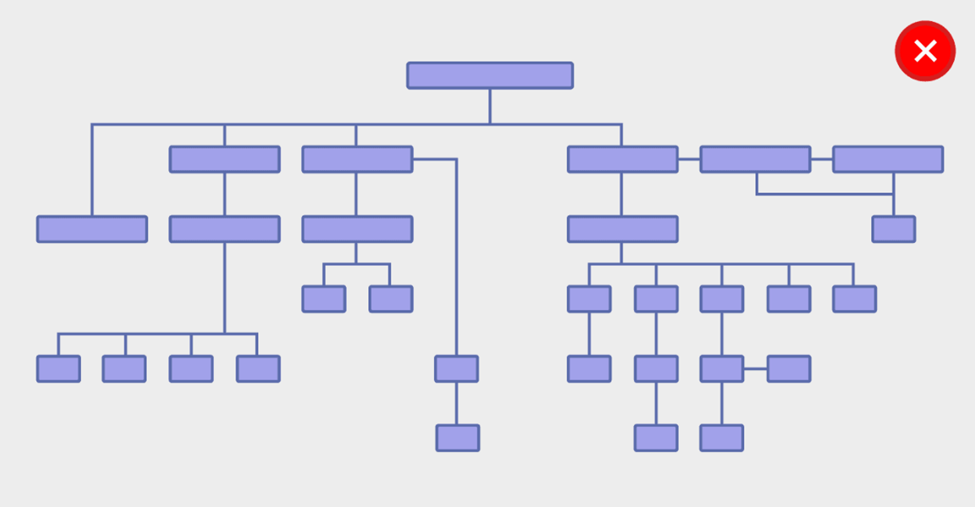
Website architecture refers to a balanced website structure for better usability and crawlability. A website with good structure helps bots to crawl each on the website more efficiently.
Here is the website with a bad structure which makes it hard for the crawl to reach to end pages of the site due to an insufficient crawl budget and bad internal linking.
Duplicate Content
Duplicate content is all content (image, text, and videos) that’s an exact copy or very similar text that appears on different pages of other sites. Avoid including duplicate content, as they compromise user experience and it can negatively impact Google rankings.
Recommendation:
- It is highly recommended to make unique content for the entire website.
- Write quality and relevant content for your users on your site for better user engagement and high ranking in SERPs.
Schema Markup
Schema markup is basically a code, also known as structured data used to clearly provide more information to search engines in order to understand your content. It creates an enhanced search result (also known as a rich snippet), which appears in search results.
An example of SERP with different schema:
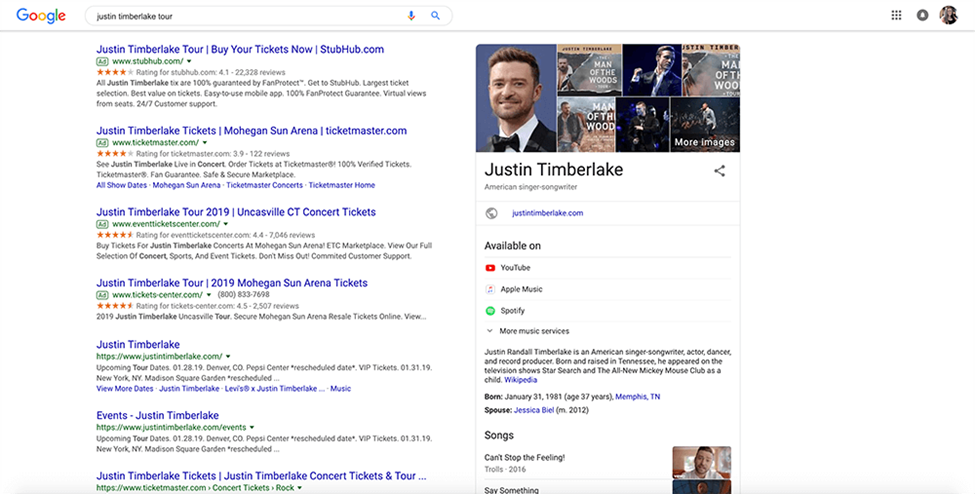
The most popular Schema markup types are Organization Schema Markup, Schema Person Markup, Schema Local Business Markup, Schema Product & Offer Markup, Breadcrumbs Markup, Schema Article Markup, Video Schema Markup, Event Schema Markup, and Recipe Schema Markup.
How to implement schema markup for your site:
- Generate the markup
- Test your code first
- Update the code straight into the head section of your page
404 Error
A 404 error page, is the content a user sees when they try to reach a non-existent page on a website. It’s the page in response by the server when it can’t find the URL request made by the user in the search box. It is can occur due to poor internal linking.
To find dead links or broken links on your site you can periodically crawl your site on Screaming Frog. It allows exporting all the 404 pages from the ‘Response Codes’ tab
Recommended: Correct and give a correct redirection links on the website.
Page Load Speed
Page speed measure the amount of time taken to load a particular page on a mobile device and desktop.
The fact that around 70% of searches are made on mobile devices by users. Improving your web page loading speed not only helps you rank higher in SERPs but also provides a great user experience and helps you high traffic on your web pages.
Following are key metrics to measure mobile site speed:
- Time to First Byte
- Requests (Fully Loaded)
- First Meaningful Paint/First Contextual Paint
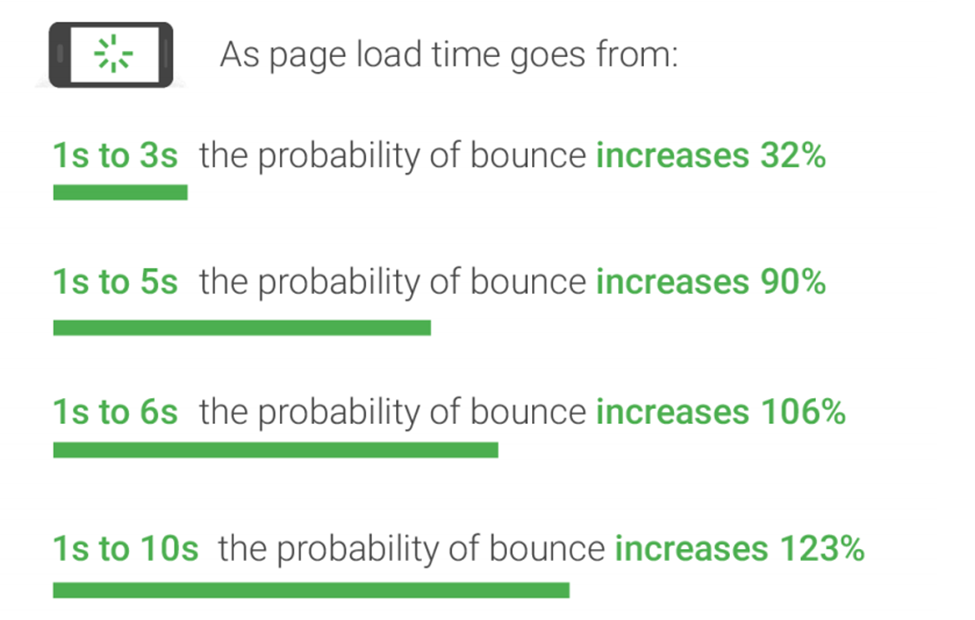
Source: Google/SOASTA Research, 2017
As you can see above image if your site loads within 3 seconds, it is faster than approximately 50% of the web, and the probability of bounce rate increase will be about 32%.
Recommendation:
- It’s always suggested to keep your mobile loading speed 3 seconds for better user experience and traffic and having recommended mobile loading speed will also help you top in SERPs.
- Use compressed images on the website in order to get a better loading speed as images take up a 60%-to-80%-page size.
- It is also recommended to minify all resources like HTML, CSS, JS, and other code on your website.
- It is also suggested that activating your browser caching to improve your page speed.
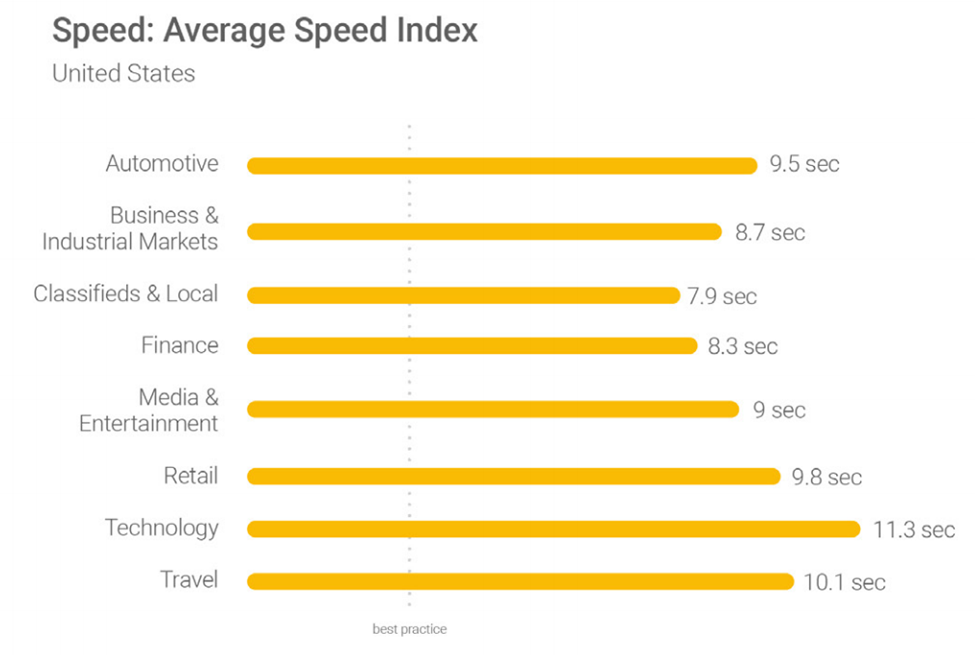
Source: Google/SOASTA Research, 2017
It is not necessary that all domain’s website will have about same loading speed across mobile devices. Each industry-oriented website will have its respective range of loading speed.
Backlink Analysis
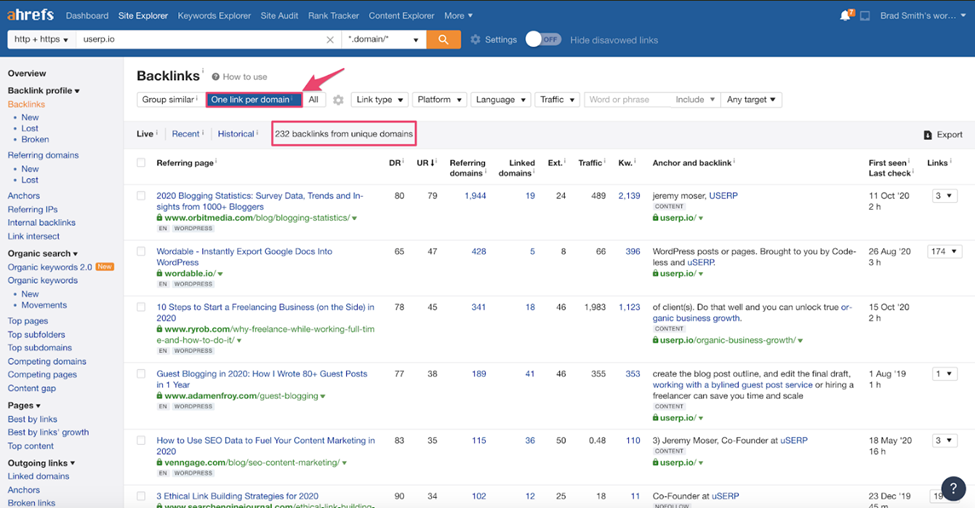
One of the most important elements is backlinks from other sites that point to your website. Search engines like Google and Bing consider these links as a sign of your site’s quality and authority, and the more you have from other reputable sites, the higher you’ll rank. Having too many spammy links can be a great indicator to search engines that a site does not have quality content.
The main objective of link analysis is to find the number of quality and relevant links and remove irrelevant bad links from the site. There are link analysis tools like Ahrefs and Moz to conduct website backlink analysis
One of the most important elements is backlinks from other sites that point to your website. Search engines like Google and Bing consider these links as a sign of your site’s quality and authority, and the more you have from other reputable sites, the higher you’ll rank. Having too many spammy links can be a great indicator to search engines that a site does not have quality content.
The main objective of link analysis is to find the number of quality and relevant links and remove irrelevant bad links from the site. There are link analysis tools like Ahrefs and Moz to conduct website backlink analysis
Security Issues
Security issues are issues like hacked URLs, deceptive pages, harmful downloads, deceptive pages and much more, which are identified by Google.
Security issues include:
- Social Engineering (Phishing and Deceptive Sites).
- Malware infection type: Server configuration.
- Malware infection type: SQL injection.
- Malware infection type: Code injection.
- Malware infection type: Error template.
- Cross-site malware warnings.
- Hacked type: Code injection.
- Hacked type: Content injection.
- Hacked type: URL injection.
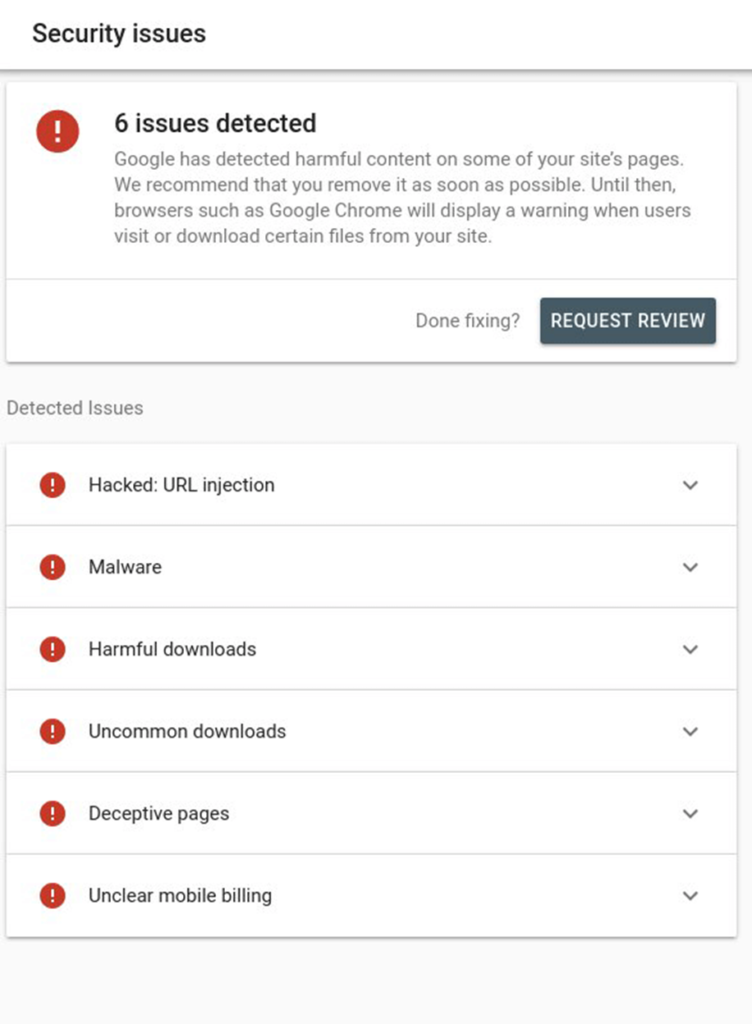
To find these issues if occur, you can log in to your search console and left side panel, scroll down to the security and manual actions section
Conclusion: Technical SEO is one of the important aspects of SEO that helps you make a website fast, decrease the loading time, and gain a better ranking in SERPs by following the Google SEO guidelines.